

When comparing dedicated vs. shared IP for email, the differences show up in the control you have, how quickly you can send, and...
Key Takeaways
- Email regex checks format only: it cannot confirm whether an address actually exists or is active.
- A well-written email regex covers the local part, the @ symbol, the domain name, and the top-level domain (TLD).
- Regex should be your first layer of validation, not your only one. Combine it with real-time email verification for reliable results.
You’ve built a signup form, and someone enters “john@” into the email field. If there’s no validation in place, that value goes straight into your database as if nothing is wrong. Then your next campaign sends to it, your ESP records a hard bounce, and your sender reputation takes a small hit over an error that was completely avoidable.
Email regex is the first layer of defense against that kind of bad data. It’s a pattern-matching rule that checks whether an input looks like a correctly structured email address before it ever gets stored or processed. Understanding how email regex works, and also where it falls short, helps you build more reliable validation into your systems.
What Is Email Regex?
A regular expression (regex) is a sequence of characters that defines a search pattern. An email regex is a pattern specifically written to match strings that conform to the structure of a valid email address.
When a user submits a form, the regex runs against the input. If the string matches the pattern ( correct characters, an @ symbol in the right place, a valid domain structure), it passes. If it doesn’t match, the form can reject the input and prompt the user to correct it.
Email regex operates at the input or form level. Its job is to catch obvious formatting errors early, before data enters your system. It doesn’t reach out to any server or check whether the address is real; it’s purely a structural check on the text itself.
Why Email Regex Matters
Every invalid address that enters your database creates a downstream problem. It contributes to bounce rates, muddies your reporting, and wastes send credits on contacts who can never receive your messages.
Regex validation catches the most obvious errors at the source: missing @ symbols, blank local parts, and malformed domain names. By filtering these out at the point of entry, you keep your database cleaner without adding any friction to your backend processes.
The impact runs across multiple teams. For marketers, cleaner intake means better deliverability from the start. For product engineers, it’s a simple, low-latency check that runs client-side or server-side without any external API calls. For data teams, it reduces the volume of records that need manual review or correction downstream.
That said, regex is efficient precisely because it’s lightweight; it only checks format. For anything beyond that, you need additional layers.
How Email Regex Works
Regex works by matching a text string against a defined pattern, character by character. Each part of the pattern describes what’s allowed: specific characters, character classes, repetition rules, or required sequences.
For an email address, the pattern needs to account for three structural parts:
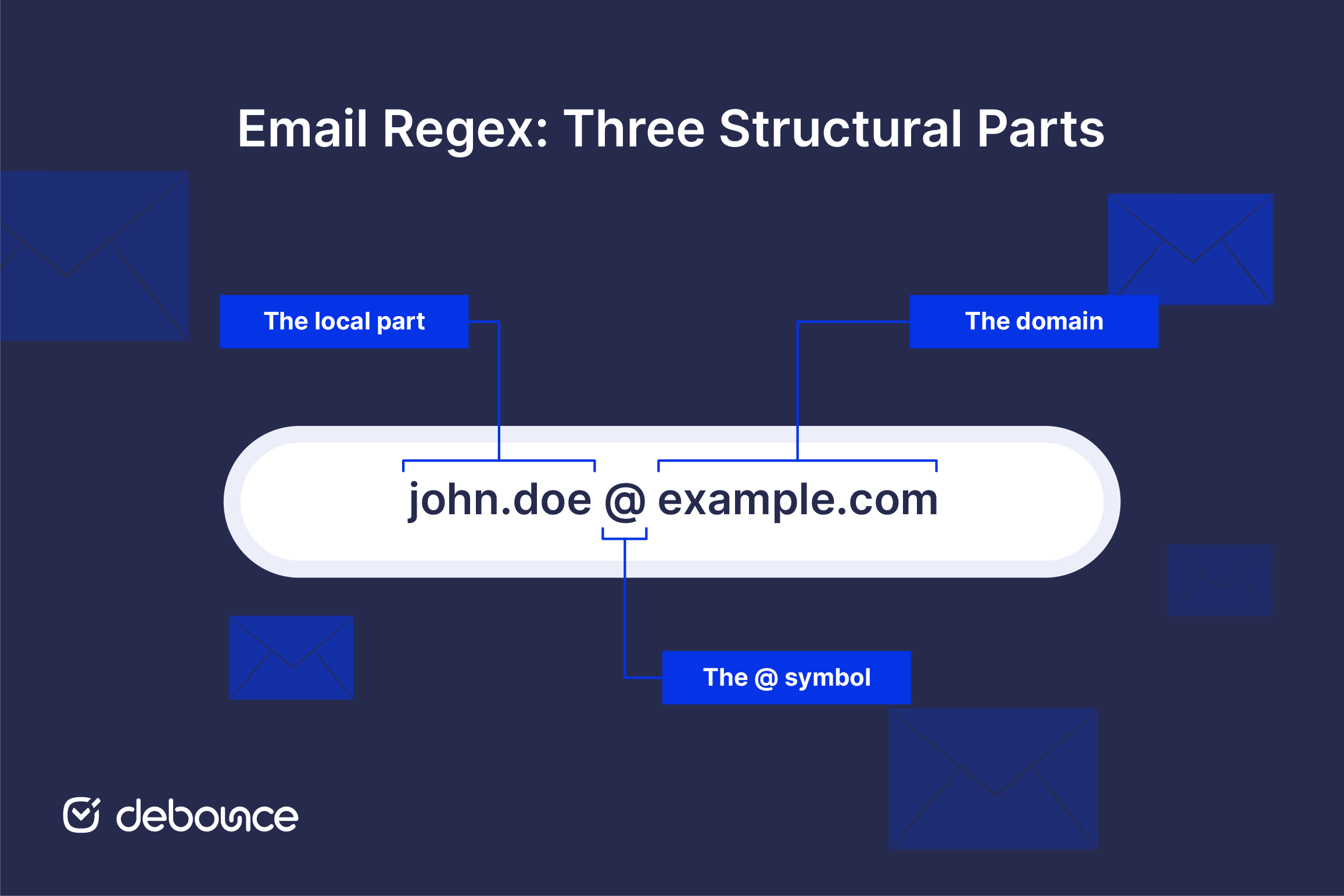
- The local part: everything before the @ symbol (e.g., john.doe)
- The @ symbol: exactly one, in the right position
- The domain: the domain name and TLD after the @ (e.g., example.com)
A basic email regex checks that all three parts are present and that the characters in each section are allowed. For example, the pattern ^[^\s@]+@[^\s@]+\.[^\s@]+$ reads as: start of string, one or more characters that aren’t a space or @, then an @, then more non-space/non-@ characters, then a dot, then more non-space/non-@ characters, end of string.
That’s a deliberately simple example. Real-world patterns get more specific depending on how strictly you want to define what counts as valid.
Common Rules Used in Email Regex
Email regex patterns follow a set of practical rules that define what a valid address looks like. They don’t cover every edge case, but they reflect the structure most systems use for everyday validation.
Local part rules (before the @):
- Letters (a–z, A–Z) and digits (0–9) are allowed.
- Special characters may include dots (.), underscores (_), hyphens (-), and plus signs (+).
- The local part cannot start or end with a dot.
- Consecutive dots (..) are not permitted.
- Length is technically capped at 64 characters per the relevant RFC specifications.
Domain rules (after the @):
- The domain must include at least one dot separating the domain name from the TLD (e.g., example.com).
- Labels between dots can contain letters, digits, and hyphens, but cannot start or end with a hyphen.
- The TLD must be at least two characters. Most modern patterns accept TLDs of varying length to cover newer extensions like .io, .museum, or .photography.
General restrictions across the whole address:
- No spaces are permitted anywhere in the address.
- The @ symbol must appear exactly once.
- The total address length should not exceed 254 characters, per RFC 5321.
Types of Email Regex Patterns
Not all email regex patterns serve the same purpose. The right choice depends on how strict your validation needs to be.
Simple patterns cover the basics: a local part, an @, a domain, and a TLD. They’re fast to write, easy to read, and work well for most standard use cases like signup forms and contact fields. The trade-off is that they may accept some strings that technically fail edge-case rules, and may also accidentally reject unusual but valid addresses.
A commonly used simple pattern in JavaScript looks like this:
/^[^\s@]+@[^\s@]+\.[^\s@]+$/
Complex patterns try to implement the full email specification more precisely. They define allowed characters explicitly, enforce dot placement rules, account for quoted strings in the local part, and handle IP address literals in the domain. These patterns are more accurate but significantly harder to read and maintain.
A more detailed pattern used in many production systems:
/^[a-zA-Z0-9._%+\-]+@[a-zA-Z0-9.\-]+\.[a-zA-Z]{2,}$/
This one explicitly lists allowed characters in the local part, allows hyphens in domain labels, and requires a TLD of at least two characters.
The practical trade-off
Simple patterns are easier to maintain and less likely to cause false rejections. Complex patterns offer tighter format enforcement but add implementation overhead. For most marketing and product use cases, a well-tested mid-complexity pattern covers the ground you need, and real-time verification handles the rest.
Best Practices for Email Validation With Regex
Regex works best when it’s treated as one part of a broader validation process. A pattern that is too strict can block valid users, while one that is too loose lets bad data through. The goal is a balance where format checks are reliable without creating friction.
- Keep your pattern readable: A regex that nobody on your team can interpret without a manual is a maintenance risk. In most cases, a clear and moderately detailed pattern is more practical than one that tries to match every edge case defined in RFC standards.

- Test against a wide range of inputs before deploying: Include edge cases like addresses with a + in the local part ([email protected]), subdomains ([email protected]), and newer TLDs ([email protected]). A pattern that fails on legitimate inputs creates friction for real users.
- Combine regex with additional verification: Regex confirms format; it can’t confirm that the address exists. For signup flows and list imports, pair format validation with a confirmation email or a real-time email verification check. This catches disposable addresses, typos in the domain, and addresses that are formatted correctly but don’t exist.
- Prioritize user experience: If your regex rejects a valid address, for example, one with a plus sign or a newer TLD, you lose a real subscriber without knowing it. It is safer to allow slightly broader input at the format stage and rely on later checks to filter out addresses that are not usable.
Common Mistakes and Limitations of Email Regex
Understanding what email regex can’t do is as important as knowing how to write it.
- Regex validates format, not existence: A string like [email protected] will pass most email regex patterns, but that doesn’t mean the address is real, active, or deliverable. Regex has no awareness of DNS, mail servers, or whether a mailbox actually exists. Format checks and deliverability checks are two separate things.
- False negatives, rejecting valid addresses: Some legitimate addresses fail overly strict patterns. Addresses with a + in the local part ([email protected]) are common for filtering purposes and are fully valid. Newer TLDs like .museum, .io, or .agency may also be rejected if your pattern enforces a two-character TLD limit. Every false rejection is a real person who couldn’t sign up.
- False positives, accepting invalid strings: Simple patterns can pass strings that look right but aren’t. For example, user@example passes many basic checks but has no valid TLD. A pattern that doesn’t enforce a minimum TLD length will accept it and store a non-deliverable address.

- Overly complex patterns break down: Patterns that try to implement the full RFC 5322 email specification can run to hundreds of characters and still fail on edge cases. They’re difficult to test, hard to debug, and often introduce new problems in trying to solve old ones. The email specification itself is complex enough that no single regex covers it perfectly.
- Regex is the first filter, not the complete solution: It catches formatting errors quickly and cheaply. For everything beyond format, including domain validity, MX records, mailbox existence, and disposable address detection, you need a verification layer. Checks like MX record lookups and full email validation go beyond regex, confirming whether an address can actually receive messages rather than just whether it looks correct.
The Bottom Line
Email regex gives you a fast, lightweight way to catch formatting errors before they enter your system. It’s worth implementing on every form and API endpoint that accepts email input. But it’s the first step in a validation workflow, not the final one.
A correctly formatted address can still be inactive, disposable, tied to a catch-all domain, or simply nonexistent. Those addresses pass regex every time. Once they’re in your database, they inflate your bounce rate, affect your email security posture, and reduce the overall reliability of your contact data.
Upload your list to DeBounce and go beyond format checks. DeBounce verifies syntax to RFC standards, checks DNS and MX records, tests mailbox existence, and flags disposable and risky address types, catching what regex can’t. Start with 100 free verifications to see exactly what’s in your list before your next send.




